


















































私的良スレ書庫
不明な単語は2ch用語を / 要望・削除依頼は掲示板へ。不適切な画像報告もこちらへどうぞ。 / 管理情報はtwitterでログインするとレス評価できます。 登録ユーザには一部の画像が表示されますので、問題のある画像や記述を含むレスに「禁」ボタンを押してください。
元スレIntel Larrabee 1コア
 Intel スレッド一覧へ / Intel とは? / 携帯版 / dat(gz)で取得 / トップメニュー
Intel スレッド一覧へ / Intel とは? / 携帯版 / dat(gz)で取得 / トップメニューみんなの評価 : ○
レスフィルター : (試験中)

larrabeeはただのチップだからマザーメーカーが勝手に乗せようと思えば乗せられる
貴重なPCIe x16を勝手に占有してなおかつ交換できないって何の拷問ですか
>>558
x86だから電力効率で相対的に不利ということは断じてないってことを言いたかった。
当然補助電源で賄いきれるだけ(300W)のTDP枠はめいっぱい使うでしょ。
それが48コア(NVIDIA換算768SP)とか言われてるわけだが。
x86だから電力効率で相対的に不利ということは断じてないってことを言いたかった。
当然補助電源で賄いきれるだけ(300W)のTDP枠はめいっぱい使うでしょ。
それが48コア(NVIDIA換算768SP)とか言われてるわけだが。
>>562
それ、いわゆるPowerVRのライセンス品なんだけど、上のグレードにしないとパワーでないよ。シャレではなく。
それ、いわゆるPowerVRのライセンス品なんだけど、上のグレードにしないとパワーでないよ。シャレではなく。
havendaleと同じタイミングでLarrabeeがでるのは
ロードマップで決まっている、
havendaleに実装されないとしたら、Larrabeeというコードネームの
CPUがでるってこと?
>>554 :Socket774:2009/01/27(火) 13:25:05 ID:YSQOzIza
> larrabeeはただのチップだからマザーメーカーが勝手に乗せようと思えば乗せられる
Larrabeeが周辺コアだとすれば、コプロってことでしょ。
それならCPUロードマップには乗せずチップセットのロードマップ上の話に
なるだろう。
かなり今年末初リリースという話が延期されていないのならば、
何かしら名前があると思う。Larrabeeチップセットか
Larrabee内蔵CPUと考えるのが妥当って話。
Larrabeeはx86命令で動くGPUという意味で作られたはずなので
PCI-e x16経由でつながるGPUという考え方もできる。
この辺てどうなのよ?
 この図だとWestmere(2010年)の前に位置している。
この図だとWestmere(2010年)の前に位置している。
ロードマップで決まっている、
havendaleに実装されないとしたら、Larrabeeというコードネームの
CPUがでるってこと?
>>554 :Socket774:2009/01/27(火) 13:25:05 ID:YSQOzIza
> larrabeeはただのチップだからマザーメーカーが勝手に乗せようと思えば乗せられる
Larrabeeが周辺コアだとすれば、コプロってことでしょ。
それならCPUロードマップには乗せずチップセットのロードマップ上の話に
なるだろう。
かなり今年末初リリースという話が延期されていないのならば、
何かしら名前があると思う。Larrabeeチップセットか
Larrabee内蔵CPUと考えるのが妥当って話。
Larrabeeはx86命令で動くGPUという意味で作られたはずなので
PCI-e x16経由でつながるGPUという考え方もできる。
この辺てどうなのよ?
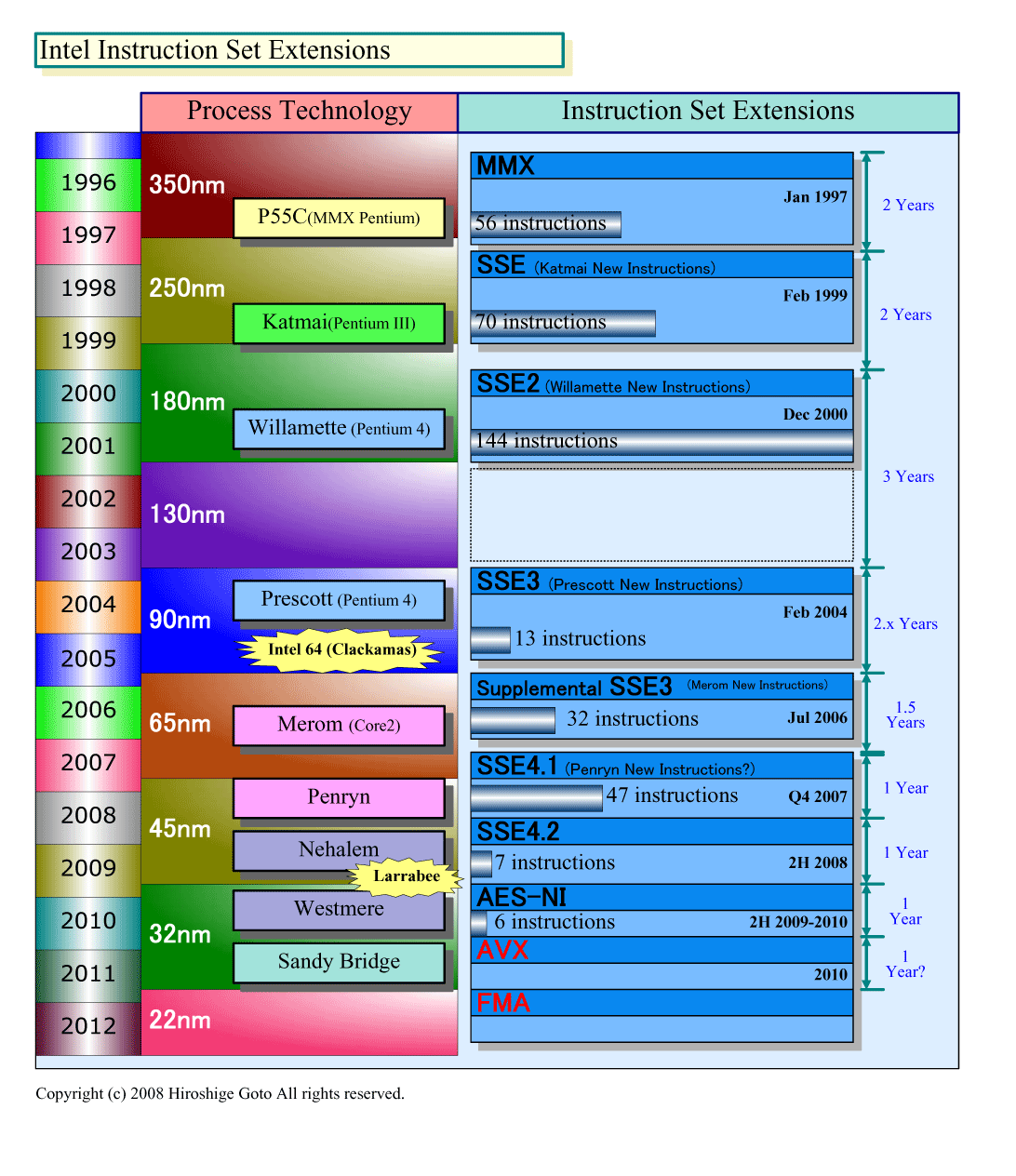 この図だとWestmere(2010年)の前に位置している。
この図だとWestmere(2010年)の前に位置している。 

まぁ、CG用のワークステーションとしては今のところコストパフォーマンス抜群だろうな
Intelが何のためにNVIDIAから大量に人材引き抜いてると思う?
i740はVRAMを出し惜しみしてた
VGA屋に不良在庫を抱えさせる功績があったインテル最高傑作
VGA屋に不良在庫を抱えさせる功績があったインテル最高傑作
Intelさまがんばってくださいいいいいいいいいいいいい!
今のNvidiaとかATIの電力食いまくり熱だしまくりの糞板を市場から廃滅してください!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
今のNvidiaとかATIの電力食いまくり熱だしまくりの糞板を市場から廃滅してください!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
そんな志の低いことをIntelがわざわざするわけ無いだろ。
10年先を見よ。
10年先を見よ。
IntelにとってGPUなんて片手間のしごとだろ
本気でやるわけないじゃん
本気でやるわけないじゃん
Intelに本気を感じた。
敢えて言おう。CtはCUDAよりよっぽどマシな言語処理系だ。
敢えて言おう。CtはCUDAよりよっぽどマシな言語処理系だ。
CUDAよりよっぽどマシくらいで盛り上がられると、とりあえず落ち着けとは思うなw
>>591
Ctってもう触れるのん?
Ctってもう触れるのん?
コーディングスタイル
http://cache-www.intel.com/cd/00/00/40/73/407336_407336.pdf
この資料の15ページ参照
さて後藤が説明してた汎用IAと IA++の混成までIntel公式の資料に出てきてしまったぞ
CUDAがまともじゃないってのは、ベクトル演算に特化しすぎてスカラで済む演算まで
無駄に並列演算してるから。このへんはハードの問題といえるかもしれない。
たとえば配列の添字あるいはポインタ算出。
Larrabeeのようなx86スカラ+ワイドSIMDなら、配列に対する連続したアドレスの算出なんて
スカラ側の演算1~2回程度で済む。(REX+)ModRM+SIB+DISPで表現可能であれば
一般のオペレーションのメモリアドレッシングモードに組み込んでしまうことができる。
で、不連続なデータにアクセスする必要があるときだけGatherオペレーションを使えばいい。
対して、CUDAはデータが連続・不連続かにかかわらずアドレス算出を1ワープ32スレッドそれぞれ
独立でやるような感じ。これで電力効率良いわけが無い。
逆説的だけど、レジスタが大量にあるのは、ロード・ストア周りの実装の非効率さを隠蔽する目的もあると思われる。
http://cache-www.intel.com/cd/00/00/40/73/407336_407336.pdf
この資料の15ページ参照
さて後藤が説明してた汎用IAと IA++の混成までIntel公式の資料に出てきてしまったぞ
CUDAがまともじゃないってのは、ベクトル演算に特化しすぎてスカラで済む演算まで
無駄に並列演算してるから。このへんはハードの問題といえるかもしれない。
たとえば配列の添字あるいはポインタ算出。
Larrabeeのようなx86スカラ+ワイドSIMDなら、配列に対する連続したアドレスの算出なんて
スカラ側の演算1~2回程度で済む。(REX+)ModRM+SIB+DISPで表現可能であれば
一般のオペレーションのメモリアドレッシングモードに組み込んでしまうことができる。
で、不連続なデータにアクセスする必要があるときだけGatherオペレーションを使えばいい。
対して、CUDAはデータが連続・不連続かにかかわらずアドレス算出を1ワープ32スレッドそれぞれ
独立でやるような感じ。これで電力効率良いわけが無い。
逆説的だけど、レジスタが大量にあるのは、ロード・ストア周りの実装の非効率さを隠蔽する目的もあると思われる。
>>582
Intelが狙ってるのはGPGPU(というより、単一の超並列演算器)であって
グラフィックに特化する事を狙ってるわけじゃないでしょ
あっちの映像処理の世界はシェーディングとかの演算に加えて、データ自体のスループットが結構重要
Intelが狙ってるのはGPGPU(というより、単一の超並列演算器)であって
グラフィックに特化する事を狙ってるわけじゃないでしょ
あっちの映像処理の世界はシェーディングとかの演算に加えて、データ自体のスループットが結構重要
 前へ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 次へ
前へ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 次へ / 要望・削除依頼は掲示板へ / 管理情報はtwitterで /
/ 要望・削除依頼は掲示板へ / 管理情報はtwitterで /  Intel スレッド一覧へ
Intel スレッド一覧へ類似してるかもしれないスレッド
- Intel Larrabee 4コア (985) - [95%] - 2009/11/26 23:47 ○
- Intel Larrabee 5コア (985) - [95%] - 2009/12/19 17:16 ○
- Intel G4X(G45/G43/G41) (727) - [27%] - 2009/8/18 5:31 ☆
トップメニューへ / →のくす牧場書庫について